Meta Flow Maps enable scalable reward alignment
University of Oxford · Harvard University · Kempner Institute
Overview
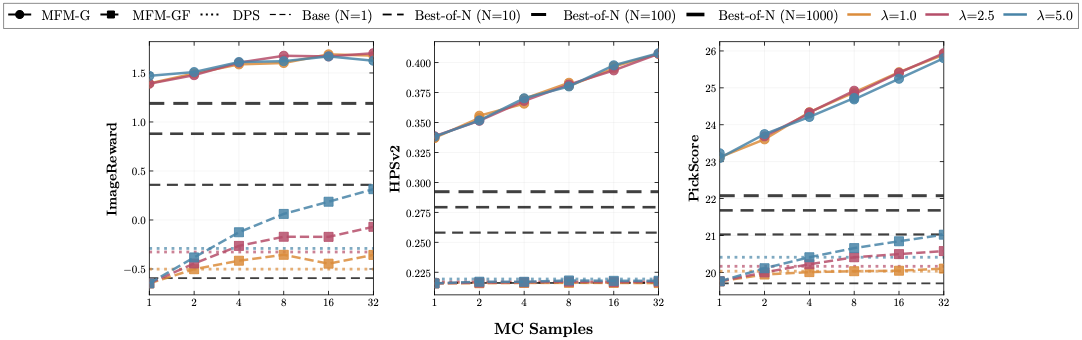
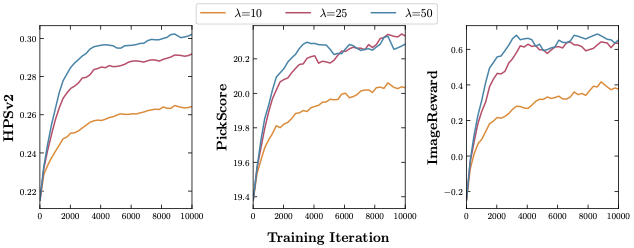
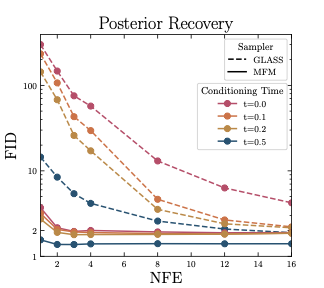
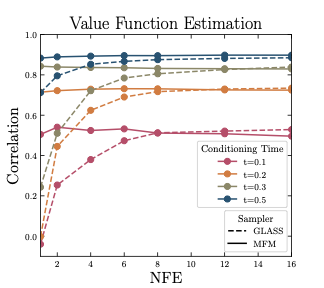
Controlling generative models is computationally expensive. Optimal alignment with a reward function requires estimating the value function, which demands access to the conditional distribution of data given a noisy sample $p_{1|t}(x_1|x_t)$—typically requiring costly trajectory simulations. We introduce Meta Flow Maps (MFMs), extending consistency models and flow maps into the stochastic regime. MFMs perform one-step posterior sampling, generating i.i.d. draws of clean data from any intermediate state with a differentiable reparametrization for efficient value function estimation. This enables inference-time steering without rollouts and unbiased off-policy fine-tuning. Our steered-MFM sampler outperforms Best-of-1000 on ImageNet at a fraction of the compute.
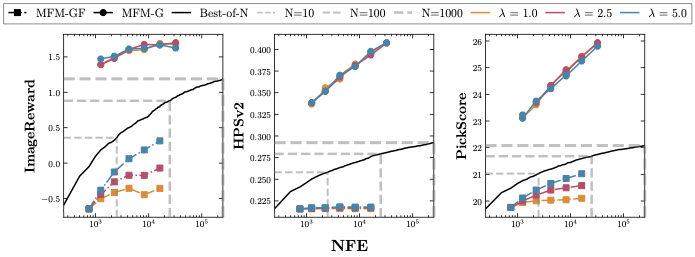
MFM steering achieves higher rewards with >100× fewer function evaluations than Best-of-N.